Rails 6, GraphQL, and database replicas!
This blog is going away soon! :( Check out my new site where you can read the latest and subscribe for updates!
Last year’s Rails 6 release included a lot of exciting features, but I was particularly amped about native multiple database support! It’s really good timing - here at First.io, we’re busy scaling up to support the RE/MAX family of real estate agents.
In the long-run, we’ll need to consider more drastic measures, such as sharded multi-region database deployments. Our initial rollout will not be huge, so we have the luxury of using more laid-back scaling techniques. A good start is making sure that read-only operations use our database replica, and write-operations use the primary database; effectively splitting the load between two DB instances.
This article steps through how we ensure GraphQL queries are routed to our database replica.
Setting up an RDS Read-Replica #
Amazon’s RDS makes it a cinch to quickly set up a replica. AWS has a comprehensive guide on setting up and working with replicas.
Even though replicas are restricted to read-only transactions, I still get peace-of-mind from adding a read-only database user. In PostgreSQL:
ALTER DEFAULT PRIVILEGES IN SCHEMA public
GRANT SELECT ON TABLES TO readonlyuser;
Accessing the replica with Rails 6 #
The Rails 6 docs have a great overview of using multiple databases. These docs walk through adding a replica to database.yml, and configuring middleware so all GET and HEAD requests are routed to the replica. Nifty!
Our setup had a caveat - we have multiple pre-production environments, but only one of them has a database replica. To address this, we added some app configuration:
config/app_config.yml
default: &default
read_replica: false
...
development:
<<: *default
...
# Other pre-prod environments follow suite
...
# This one has a replica
qa:
<<: *default
read_replica: true
production:
<<: *default
read_replica: true
Then in app/models/application_record.rb:
if MyApp::AppConfig[:read_replica]
connects_to database: { writing: :primary, reading: :primary_replica }
else
connects_to database: { writing: :primary, reading: :primary }
end
Otherwise, Rails won’t know what you mean when you refer to different database roles.
We also wrap a few complex, admin-oriented CSV exports like so:
ActiveRecord::Base.connected_to(role: :reading) do
# Do export stuff
...
end
This was actually our original use case for a replica - these CSV exports were needed on a daily basis by our Ops team, but would completely tie up DB resources when running, which severely impacted user-facing app performance.
First’s Application Architecture #
After adding the DB replica and basic request routing, our architecture looks like this:
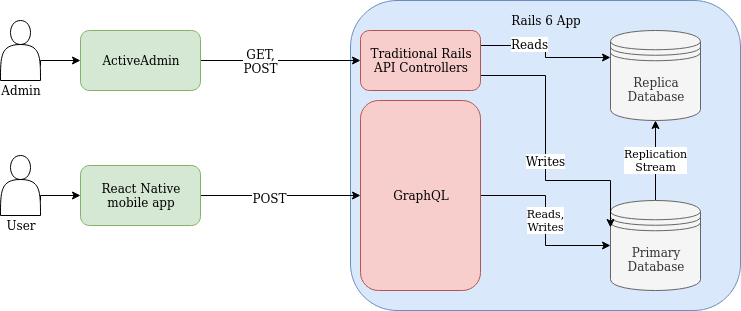
- Rails 6 backend
- Primary DB used for background processing jobs, and requests involving DB updates (
POST,PATCH, etc.) - Replica DB used for complex data exports and for read-only requests (
GETandHEAD) - Active Admin interface for internal users - with those requests routed to the appropriate DB via our middleware config
- GraphQL API (implemented via graphql-ruby)
- Primary DB used for background processing jobs, and requests involving DB updates (
- React Native mobile front-end
- Interacts with our API via Apollo GraphQL Client
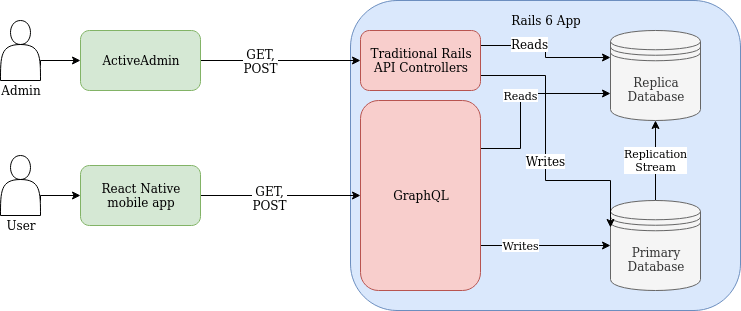
GET requests with GraphQL #
If you’re familiar with GraphQL, you might see the problem here. All GraphQL operations - including read-only queries - are sent via POST requests. Given how our Rails middleware is configured above, this means all GraphQL requests will use the primary database, and our users won’t benefit from the awesome replica we set up.
Thankfully, the Apollo Client has a great solution for this - a one-line config option allows you to perform queries as a GET rather than a POST:
export const httpLink = new HttpLink({
uri: `${ENV.host}/graphql`,
useGETForQueries: true,
...
})
We also must set up a GraphQL GET route in Rails:
config/routes.rb
...
post "/graphql", to: "graphql#my_schema"
get "/graphql", to: "graphql#my_schema"
...
And make sure we can handle variables passed as a query string parameter in a GET request:
graphql_controller.rb
private
def variables
if params[:variables].is_a? String
JSON.parse(params[:variables])
else
params[:variables]
end
end
public
def my_schema
query = params[:query]
operation_name = params[:operationName]
context = {
current_user: current_user,
}
result = MyAppSchema.execute(query, variables: variables, context: context, operation_name: operation_name)
render json: result
end
Now, our architecture resembles this:
Gotchas #
Like any solution, there were a few finer points that snuck up on us either during QA or after deployment.
- Query caching takes time to catch up
- PostgreSQL does some very smart query result and plan caching - which does not get replicated
- This means some initial queries will be slower than you might see pre-database-switching, but will catch up as the cache is built
- Mutations masquerading as queries
- We had one specific GraphQL query -
ExportContactsCSV- which was defined as a query because it didn’t require any parameters - It’s primary purpose is to enqueue a background job, but a database record is created for idempotency purposes
- We had to switch this to a proper mutation, otherwise the operation would fail
- Before switching your request routing, it’s best to do a quick audit of your queries to make sure they’re not actually updating any database records
- We had one specific GraphQL query -
- Similar to the above point on mutations, we had a couple of Active Admin
showmethods that were performing updates under-the-covers- The ideal is to separate concerns as best as possible, but if it’s not, you can add one-off database routing:
def show
ActiveRecord::Base.connected_to(role: :writing) do
# Do export stuff
...
end
end
We’re Hiring! #
If you’re interested in the tech stack above, and want to work on a fast-scaling app, you’re in luck! We’re looking for a front-end engineer to join our team!
Feel free to connect with me!
- www.linkedin.com/in/jeremiah-coleman-product
- https://twitter.com/nerds_s
- jeremiah.coleman@daasnerds.com
- https://github.com/colemanja91