Scaling Marketing Data Pipelines
This blog is going away soon! :( Check out my new site where you can read the latest and subscribe for updates!
Lessons from Site Reliability Engineering: Part 2 #
If you’ve ever felt overwhelmed by the choices of vendors and tools available for data-driven marketing automation, you are far from alone. The need for operational, time-sensitive data pipelines is skyrocketing, mostly driven by the demand for fast response times expected by most customers.
When you break the problems/solutions of data processing down to it’s components, there are three phases of evolution that data pipelines go through: Entry-Level, basic functionality provided by many platforms; Mid-Level, usually custom scripted and implemented in-house; and Big Data, which turns marketing automation standards on their heads in order to innovate.
Operational / Time-Sensitive vs. Reporting #
Before we dive in, it’s important to understand the two types of data pipelines typical to marketing operations. (However, the paradigm is not exclusive to marketing data).
While reporting pipelines are essential to long-term marketing optimization, our focus here will be on operational pipelines. These are defined as any time-sensitive data flow on which day-to-day business depends.
The example I most commonly use is a “Contact Sales” web form: when a visitor wants to purchase your products or services, they fill out this form, which then hits a data intake system. Then, multiple processes fire off to create an appropriate lead in a CRM system, route to the appropriate teams, send a confirmation email to the visitor, and possibly drop in to a related cross-sell/up-sell nurture flow.
The key difference here is the downstream impact of pipeline issues. If a dashboard user notices an issue with the business logic traced back to an ETL, it can easily be fixed in the next scheduled release. If a “Contact Sales” submission falls through the cracks, it results in immediate lost revenue for the business. For these pipelines, it’s essential to have a reliable development, testing, and release process, as well as monitoring to ensure data keeps moving.
Let’s look at a few examples of reporting and operational data pipelines:
Reporting:
- Dashboards (Qlik, Tableau)
- Performance Review and Planning
Operational and Time-Sensitive:
- Lead and Campaign Membership Creation
- Lead Scoring
- Nurture track assignment
- Web Tracking and Personalization
Now we can dive in to the progression of operational data pipeline tools.
Entry-Level #
Basic data flow tools are natively available in most marketing automation platforms (MAPs), usually as a drag-and-drop interface with a standard set of data selections:
- Program Builder/Program Canvas/Campaign Canvas (Eloqua)
- Workflows (Hubspot)
- Programs (Marketo)
Depending on product and configuration, they offer anywhere from near-real time batch(<2min) to macro-batch (>15min) processing times. All processing takes place “behind the scenes” within the MAP.
Pros:
- Easy to get started: low barriers to entry as no coding experience required
- Increased transparency: simple data flows are easily explained to non-technical users
- Plug-and-play: most MAPs offer support for third-party plugins (such as Eloqua’s AppCloud Apps) which expand functionality
Where scale and reliability become issues:
- No version control: changes to critical processes (such as lead creation and syncing with a CRM) cannot be easily tracked or reverted
- Limited tracking*: little/no logging makes troubleshooting an extremely manual and time-consuming process
- No native monitoring: related to limited tracking, users are completely dependent on a vendor for site reliability; monitoring can be set up custom but is usually very roundabout
- Lower environments: no sandbox available (or no way to migrate configurations from sandbox), which results in most changes being made directly in production
Mid-Size #
The next step is often an in-situ transformation - data is exported (on a scheduled basis) via an API, a scripted process applies transformations (or integrates with other systems, such as a CRM), and at the end of processing the data is returned (in either a modified or enriched state) to the marketing platform.
Processing can occur at nearly any range, from minutely to daily, usually with the limitation of streaming/real-time processing being excluded.
Common tools include:
- Apache Airflow
- Luigi (Spotify)
- Conductor (by Netflix)
Pros:
- Version control, lower environments: use Git, run your code in DEV/QA/STAGE/PROD (or however many you wish)
- Open Source: pipelines use common tools and standards, and prevent risk of vendor lock-in
- Complex conditions and actions: logic which is impossible (or nearly-impossible) in a MAP is easily implemented in a few lines of code
Where scale and reliability become issues:
- Infrastructure burden: setting up, monitoring, and maintaining application platforms can quickly eat up most development time (can be alleviated if company has/uses a dedicated PaaS service)
- Data versioning and audit: high number of distinct touch-points (multiple scripted processes, manual edits/uploads within the MAP, etc) can prove difficult when troubleshooting issues; also, these data systems usually do not have a “rollback” capability
- Reduced transparency: pipeline tools available in most MAPs are easy for business users to follow, but code is (usually) not; requires developers to be proficient at working with the business
Big Data #
For groups wanting to be exceedingly innovative, the next logical step is using a big data platform. In this case, the big data platform becomes the focal point of the data, with the MAP being an integration on the periphery.
- Google Cloud Platform (Apache Spark & Hadoop, Pub/Sub, BigQuery, and managed databases)
- Microsoft Azure (support with Databricks Spark-as-a-Service recently announced)
- Amazon EMR + Databricks (Apache Spark)
- Confluent Cloud (Apache Kafka)
Pros:
- Managed services: similar to using a MAP, no worries about infrastructure or resource provisioning; but you completely own your code, functionality, and logging
- Proven at scale: Apache projects Spark and Kafka are used by companies such as Netflix, AirBnB, Paypal, and CapitalOne
- Fully-integrated pipelines: connecting components is commonplace and usually as simple as adding a library
- Variety of languages: most solutions offer APIs in established languages, such as Java, Scala, Python, R, and SQL; makes the engineering talent search a bit easier
- Ease of monitoring: use Grafana, Prometheus, or nearly any other monitoring system out there; best of all, focus only on your pipelines, without wasting time watching the infrastructure
Where does Marketing Automation live? #
Transitioning to big data comes with a fundamental shift in marketing automation architecture. In the Entry-Level and Mid-Size solutions above, the MAP is at the center of the data, acting in it’s own as a data management platform (DMP).
Big data requires infrastructure and flexibility that most MAPs can’t keep up with, so we keep the MAP doing what it’s good at: usually, this is sending and tracking emails. The end result is the high-level architecture shown below:
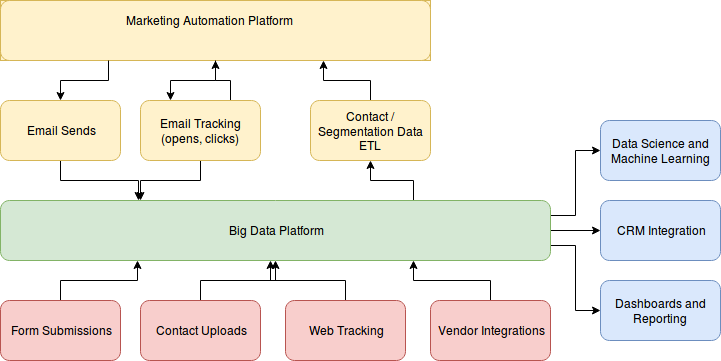
This design has many benefits, which I hope to dive into in future articles.
Where are the microservices? #
Microservice APIs are all the rage these days - especially in context of moving away from monolithic applications (i.e., marketing automation platforms). While I plan to address microservices in relation to data engineering and marketing automation later, I’ll give a few high-level points here.
Microservices are helpful for:
- Business logic which may be used in other contexts (i.e., a UI which allows business users to interact with the logic)
- Logic or pipelines owned by another business unit - unfortunately, data silos are still very common, but microservices can provide enough of an opening for collaboration
But are less useful for:
- Maintaining large data stores
- Scheduled processes
- Logic which only has one isolated use case in scope of a larger pipeline
Conclusion #
The landscape of data pipelines is rapidly changing, and marketing automation experts must keep up to meet business demands. Operational pipelines are time-sensitive data transformations and integrations which keep the business moving day-to-day.
At the Entry-Level, most Marketing Automation Platforms provide the necessary tools for basic business processes. Companies who grow more complex usually require pipeline development outside of their MAP. Those seeking to use data in a game-changing way transition completely outside the MAP to a big data platform.
Feel free to connect with me!
- www.linkedin.com/in/jeremiah-coleman-product
- https://twitter.com/nerds_s
- jeremiah.coleman@daasnerds.com
- https://github.com/colemanja91